��ʵ������վ�������dz�������Ҳ�dz��ߣ�������ȴ������Ϊ��web������ʵ�֣���ֻҪ������վ�ij�ֵľ�̬�����ಿ��̨����������ô��������������˶���������վҲ���������С�
AD��
ǰ���ù�˾������λ��������ļ�����ţ��������һ�δ�����վ�ܹ�����ѵ������12��Сʱ��Ϣ���dz���֪ʶ�Ĺ�Ⱥ��Ѷ�Ҳ�dz�����ѵ��������������ȫ��������֪ʶ�����컻�˸�˼·�ǻ�ζ�����ѵ�����˼·����ͨ������Ŀǰ�ľ���ͼ���ˮƽ��˼���´�����վ�����ݽ��Ĺ��̡�
������Ҫ˼��һ�����⣬ʲô������վ���Ǵ�����վ������վ�ļ���ָ��Ƕȿ�������������Ǻ�����һ��ë��������Ϊ��վ�ķ������Ǻ�����ָ�꣬�����е���Ҳ������Ϊ����վ�ڵ�λʱ����IJ������Ĵ�С����Ϊָ�꣬�������Щ����ô��hao123��������վ���Ǵ�����վ�ˣ�����ͼ��ʾ��
��ʵ������վ�������dz�������Ҳ�dz��ߣ�������ȴ������Ϊ��web������ʵ�֣���ֻҪ������վ�ij�ֵľ�̬�����ಿ��̨����������ô��������������˶���������վҲ���������С�
���ô�����վ�Ǽ�����ҵ��Ľ�ϣ�һ������ijЩ�û��������վֻҪ������ҵ�������һ���ѶȺܴ�Ȼ������ҵͶ�����ġ�������������ɱ�ʵ��������ô��������վ������ν�Ĵ�����վ�ˡ�
һ����������վ�����û�Ⱥ���Ǻ�С�ģ������վ�ܹ����ܽ��ʵ�ʵ��û�����ȻΪ�˱�֤��վ���ȶ��ԺͰ�ȫ�ԣ��ǻ����վ��Ӧ�ò���������̨�����ϣ���̨�Ĵ洢ʹ�����ݿ⣬�������ʵ�����������ݿ�ʹ�õ�̨����������������������վ�������ߣ�����dz�����Ѳ������ݿ�ķ�����ʹ�õĺõ㣬�����վ�ṹ������ʾ��
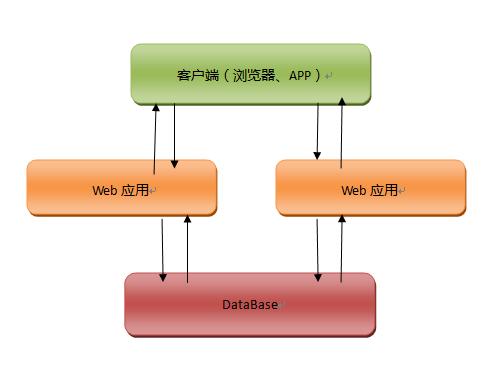
����ṹ�dz�����ʵ�ֳ�����վ����������ҵ����û����ҵ��ϵͳ��ô���ӣ�����ֻҪ�и��õ�idea������һ������վ�ijɱ��Ƿdz��͵ģ���ʹ�õļ����ֶ�Ҳ�Ƿdz��Ļ����ͼ�������ͼ��Ҫ����̨�����������һ�Ҫ������������ǵķ���������Щ�ɱ����ڲݸ��͌�˿���Ƿdz��ߵģ����˵��ǵ��ºܶ��˾�ͻ����ṩ����ƽ̨���ǿ��Ի��Ѻ��ٵ�Ǯ���Լ���Ӧ�ò�����ƽ̨�ϣ�������������������ȥ���ǰ�Ӧ�á����ݿ�ֿ���������⣬���ӽ�һ���Ľ�������վ��������ά�ijɱ���������������Ҳ��һ�����⣬������վ��С���������ƽ̨��ס�ˣ������ƽ̨���ˣ����ǵ���վ����Ҳ���Ź��ˡ�
�����Ƚ����Լ�����ʹ�÷�����������վ�����⣬�����Ҫ����վ����Ӧ��ʹ�ö�̨������������ô����Ŀ��һ����������
��֤��վ�Ŀ����ԣ���̨����������Ӧ�ã���ô����һЩ�������ҵ��ˣ�ֻҪ��վ���з�������������ת����ô��վ������Ȼ���������ṩ����
�����վ�IJ�������������Խ����ô��վ�ܹ�������û�����λʱ�����ܳ��ص�������Ҳ��Խ��
����Ҫ�����������㣬�������Ǽ���վ�ֿ�����Ϳ�������ģ���Ϊ�������վ���û�ʹ��ʱ����Ҫ�����û���״̬������������վҪ��ס�����ǹ�������һ���ͻ��ˣ������״̬����վ���������ͨ���Ựsession�����ֵġ��ֿ������webӦ�÷���Ҫ�����һ����Ҫ�������Ҫ���ֲ�ͬ�������������֮���sessionͬ�����⣬�Ӷ��ﵽ���û���һ��������ʵ�������A���ڶ���������ʵ�������B����վ��Ȼ֪��������������ͬһ���ˣ����������ֱ�ӣ�������A�ͷ�����B�ϵ�session��ϢҪʱ�̱���ͬ������ô��α�֤��̨������֮��session��Ϣ��ͬ���أ�
Ϊ�˻ش���������⣬������Ҫ������session�Ļ��ƣ�session��Ϣ��web�����ﶼ�Ǵ洢���ڴ���ģ�web�������ÿ���������Ŀͻ�������һ��sessionidֵ�����sessionidֵ�ᱻweb��������httpЭ�����cookie���£�����Ӧ���ͻ��˴����ͻ��˱��ػ�洢���sessionidֵ���û��Ժ��ÿ�����������sessionidֵ��cookieһ�ݵ���������������ͨ��sessionid�ҵ��ڴ��д洢�ĸ��û���session���ݣ�session���ڴ�����ݽṹ��һ��map�ĸ�ʽ����ôΪ�˱�֤��ͬ������֮���session��������ô��ֱ�ӵķ��������÷�����֮��session���ϵĴ��ݺ��ƣ�����java�����ﳣ�õ�tomcat�����Ͳ������ַ�������ǰ���Թ�tomcat����sessionͬ�������ܣ����ֵ���Ҫͬ����web����Խ�࣬webӦ�����ܳ��صIJ�������û����Ϊ�����������Ӷ������������������������ﵽһ���ٽ�ֵ������webӦ�õIJ��������������½���Ϊʲô�������ˣ�
ԭ��ܼ���ͬ������֮��session�Ĵ��ݺ��ƻ����ķ�����������ϵͳ��Դ��������������Խ�����ĵ���ԴԽ�࣬���û�����ԽƵ����ϵͳ������ԴҲ��Խ��Խ������Ƕಿ���������Ŀ��ֻ���뱣֤ϵͳ���ȶ��ԣ��������ַ������Dz����ģ�����webӦ����ò����ٵ㣬�����Ų���Ӱ�쵽webӦ�õ��������⣬����ǻ���������վ�IJ�������ô�͵ò�ȡ�����ķ����ˡ�
ʱ��ʹ�õıȽ϶�ķ�������ʹ�ö����Ļ����������Ҳ���ǽ�session�����ݴ洢��һ̨�����ķ������ϣ�������ô���һ̨����������ȫ����ô����ʹ��memcached�����ķֲ�ʽ������������д洢�������ȿ�����������վ�ȶ�������Ҳ��������վ�IJ���������
�������ڵ��Ա����������������������ǽ�session����Ϣֱ�Ӵ洢���������cookie�ÿ������cookie��Ϣ��������httpһ�ݵ�web�������������ͱ�����web������֮��session��Ϣͬ�������⣬���ַ������úܶ���ڸ����ڸ����ԭ����cookie�IJ���ȫ����������֪�ģ�������˶����ȡcookie��Ϣ��ô��վ���Ͳ���ȫ��������𰸻��治��˵�����Ǿ����ǽ����Ǹ����û���״̬����session����cookie����ʵҲûʲô���˵ġ�
��ʵ���רҵ���Ա���ô����ʵ���Ǻ�������ģ����ǵñ��Ŀ�ƪ�ᵽ��hao123��վ�����ǿ��Գ��ظ߲�������վ����֮���Կ���������һ�㣬ԭ��ܼ����Ǹ���̬��վ����̬��վ���ص���Dz���Ҫ��¼�û���״̬����̬��վ�ķ���������Ҫʹ�ñ����ϵͳ��Դ���洢������session�Ự��Ϣ�����������и���ϵͳ��Դ���������������Ա���cookie���ڿͻ���Ҳ��Ϊ�˴ﵽ������Ŀ�ģ���������������Ա���վ�ܹ��ﻹ��ʹ���˺ܳ�ʱ��ġ�
�ڹ�˾��ͻ��˵�����web������֮ǰ�����ȵ�F5��F5��һ�����������ؾ����Ӳ���豸�����������ǽ��û�������ȵķַ�����̨�ķ�������Ⱥ��F5��Ӳ���ĸ��ؾ����������������û��ô��Ǯ���������豸��Ҳ�������ĸ��ؾ���������������������Ǵ���������LVS�ˣ���Щ���ؾ����豸���˿��Էַ����������ǻ��и���������������Ǹ���httpЭ����ص���Ƶģ�һ��http����ӿͻ��˵������յĴ洢������֮ǰ���ܻᾭ���ܶͬ���豸������ǰ�һ������������ٹ�·�ϵ�һ����������Щ�豸Ҳ���Խ�����Щ�ڵ���Ǹ���·�ϵ��շ�վ����Щ�շ�վ���ܸ����Լ�������ı�http���ĵ����ݣ����Ը��ؾ����豸���Լ�סÿ��sessionidֵ��Ӧ�ĺ�̨����������һ������sessionidֵ������ͨ�����ؾ����豸ʱ���ؾ����豸����ݸ�sessionidֱֵ���ҵ�ָ����web�����������������и�ר�����ʾ���sessionճ�ͣ���������Ҳ������session��Ϣ�ڲ�ͬ������֮�俽������Ҫ��Ч���������������DZȴ�cookie��Ч�ʵ��£����Ҷ�����վ���ȶ���Ҳ��һ��Ӱ�켴���ij̨�������ҵ��ˣ���ô���ӵ��÷��������û��ĻỰ����ʧЧ��
���session������ı���Ҳ���ǽ��session�Ĵ洢���⣬�䱾��Ҳ���ǽ����վ�Ĵ洢���⣬һ����������վ�����ڵ���Ӫ����Ҫ�����������������ɴ洢���µġ��������ᵽʱ�ºܶ��½���webӦ�ûὫ�������������ƽ̨��õ���ƽ̨�����������ǽ�����ؾ����sessionͬ�������⣬������ƽ̨���и�������ѽ���Ǿ������ݿ�Ĵ洢���⣬�����ʹ�õ���ƽ̨�������ش��¹ʣ�������ƽ̨�洢�����ݶ�ʧ�����ֻ�ᵼ��������ƽ̨�����ݿ����ϢҲ�ᶪʧ�ˣ���Ȼ�������ĸ��ʲ��ߣ����Ƿ�����������ļ��ʻ����еģ���Ȼ�ܶ���ƽ̨�������Լ���ô�ɿ���������ʵ�ɿ����ж�߲��Ǿ����˻��治���Ŷ�����ʹ����ƽ̨����Ҫ���ǵľ���Ҫ�������ݱ��ݣ������淢�������ݶ�ʧ������һ�����ٳɳ�����վ���Կ��ܷdz�������
д������һ��Ӥ�������վ���������Ǵ�������ˣ���ϣ����վ�ܽ������ٵijɳ��������վ��İ���Ԥ�ڳɳ��ˣ���ôһ������һ��������ı������Ѿ����㲻����ʵ���������ʱ����Ӧ����ξ����ˣ�������ȫ��������ʹ���µļܹ���������ǰ�����SOA�ܹ����ֲ�ʽ�����������������������SOA�ͷֲ�ʽ�����Ǻ��ѵģ��ɱ��Ǻܸߵģ������ʱ����ͨ�����Ӽ�̨���������ܽ������Ļ����Ǿ��Բ�Ҫȥѡ��ʲô�ֲ�ʽ��������Ϊ����ɱ�̫���ˡ����潲������session�����ķ�����������������Ӧ�õ�ˮƽ��չ���⣬��ô������վ����ƿ��ʱ��Ͷ�Ӽ�̨������������������ô������и������ˣ�����վ�ɳ��ܿ죬��վ����������ƿ���������ĸ���������⣿
��������������վ�ģ�����������վ�и��ص���ǵ��û����ʵ�����������վʱ��Ŀ�Ķ�����ȷ����Ϊ�˸�Ǯ���û���������������վʱ��ϣ���ܿ�㣬�ٿ����ɱ���վ�IJ������ܶ��û���ʹ����������վʱ��̫ȥ������վ���������ݣ��������������վ��������ݿ���Ծ��Ƕ�д������ʵ�dz��ľ��ȣ������ܶೡ��д�ȶ�Ҫ�ߣ�����ص��Ǻܶ�רҵ������վ���ص㣬��ʵ��������վ����ҵ�������ص�����ƣ�ҵ���������Ҫ�ȳ�����ҵ��չʾ����Ҫ�ȣ����רҵ����վ������ҵϵͳ�������ص�Ƚ϶ࡣ���Ǵ����ճ����õ���վ���Ƕ���ʱ��ܳ�����վ�����ݿ�Ƕȶ��������Ƕ�ԶԶ����д��������ڵ�����վ���Ķ�д����������9��1��
12306�������й�����������վ֮һ���ǵ�12306���ھ�������һ����������û���¼���ǵDz��ϣ������ڸ߷���������վ�ҵ���ҳ����ʾ503��վ�ܾ����ʵ����⣬�������ܺ����������վ�������ˣ�������ȥ��¼��վ����Ʊ��ϵͳ�ҵ��ˣ�������е��˶�����ʹ����վ�ˡ�����վ����503�ܾ�����ʱ����ô�����վ�ͳ����������������⣬������û����ʵ�ȷ�Ǹ��������⣬���ǵ��߲���������ʱ��������վ������ʹ�����ֻ��˵��վ����Ϸ�������������һ���õ���վ�����Ӧ�Գ����Լ������IJ���ʱ��������Ӧ���Dz������ҵ�����Ϊ���ֽ����˭������ʹ�ã���ϣ����Щ�ڿɽ��ܵ������£����ڿɽ�������Χ�ڵ������ǿ�������ʹ�ã�������������Ա��ܾ����������Ǿ��Բ���Ӱ�쵽ȫ��վ���ȶ��ԣ������ǿ�����12306��վ�ķ�ֵ��δ���ٹ���������Խ��Խ�࣬����12306����ȫվ�ҵ���������Խ��Խ���ˡ�ͨ��12036��վ�ı��Ǹ���һ��˼������վ��ƿ�����⡣
�ų�һЩ���ɿص����أ���վ�ڸ߲����¹ҵ���ԭ��90%������Ϊ���ݿⲻ���ظ����£���Ӧ�õ�ƿ������ֻ���ڽ���˴洢ƿ����Żᱩ¶����ô��Ҫ������վ�����ĵ�һ�����������������ݿ�ij������������ڶ�Զ����д����վ�Dz�ȡ�ķ�ʽ���ǽ����ݿ�Ӷ�д����ǶȲ�֣�����������ǽ����ݿ��д���룬����ͼ��ʾ��
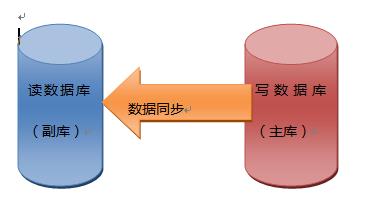
����ʱҪ����������ݿ⣬һ�����ݿ���Ҫ����д�����dz�֮Ϊ���⣬һ�����ݿ�ר�Ÿ���������dz�֮Ϊ���⣬��������ݶ��Ǵ������ģ����ݿ�Ķ�д���������Ч�ı�֤�ؼ����ݵİ�ȫ�ԣ������и�ȱ����ǵ��û��������ʱ�������ݶ����е���ʱ��������ʱ����ȫվ�������ǿ϶��ǿ��Խ��ܵġ��������12306�ij�����������д���뻹��ԶԶ�����ģ��ر��Ǹ���������ĸ��⣬�ڸ߷�����Ҳ�Ǻ����״ﵽ���ܵ�ƿ���ģ���ô�Ǿ͵�ʹ���µĽ��������ʹ�÷ֲ�ʽ���棬���������ȱ����Dz�����Ч��ʵʱ���£������ʹ�û���ǰ����Ҫ�Զ����������ݽ��з��࣬������Щ�����������仯�����ݿ������ȴ�ŵ����������ķ���Ч�ʺܸߣ��������ö����Ӹ�Ч��ͬʱҲ���������ݿ�ķ���ѹ������������д���������⣬��Ϊ����վ��д�ı���������ʧ�⣬����������ﵽƿ�����DZȽ��ѵģ���������Ҳ��һ������ѹ������������������ͬ�����⣬����ͬ��ʱ�����ݶ����������������������������������������ݶ�ȡ��������ȡ�����ر�࣬�����ﵽƿ��������һ�����Ѷȵġ�����˵������ţ�Ƶ�facebook�����ݵ��κβ����������Ⱥϲ�Ϊ�����������Ӷ��ﵽ�������ݿ�ѹ����Ŀ�ġ�
����ķ����ǿ��Ա�֤�ڸ߲�������վ���ȶ��ԣ���������ڶ������������̫���ˣ�������վ���ҵ��ˣ��û��ܺܿ���ں������������������Ҫ����Ϣ�ֳ�Ϊ����վ��һ��ƿ��������û���Ҫ�ܳ�ʱ����ܻ���Լ���Ҫ�����ݣ��ܶ��û���ʧȥ���ĴӶ���������վ��ʹ�ã���ô��������ָ���ν���ˣ�
������������Ǿ���ʹ�õİٶȣ��ȸ�������������ں������ݵĶ��ǿ��Բ��������������ǿ��Խ����ݿ�����ݵ������ļ�����ļ�����������ʹ�õ�������������������Ϣ���ǿ����˰ٶȣ��ȸ�����������������Ϣ����Ȼ�ܺܿ�ļ��������ݣ����������ǽ�����ٶ�ȡ���ݵ�һ����Ч���������������ȡ���Ǻ����ݿ�Ķ�ȡ��������ģ�����û���ѯ��������ͨ�����ݿ�������ֶΣ�������ͨ������ȷ�Ľ������������ֶ�����������ô���ݿ�IJ�ѯЧ���Ǻܸߵģ�����ʹ����վ���˸�ϲ��ʹ��һЩģ����ѯ�������Լ�����Ϣ����ô������������ݿ�����Ǹ�like������like���������ݿ���Ч���Ǻܵ͵ģ����ʱ��ʹ���������������ƾͷdz������ˣ����������dz��ʺ���ģ����ѯ������
OK�������ˣ����ڴ洢����������д�������һƪ������������⽲�⣬����洢�����Ǻܸ��ӵģ���ƪ��������ϸ�㡣